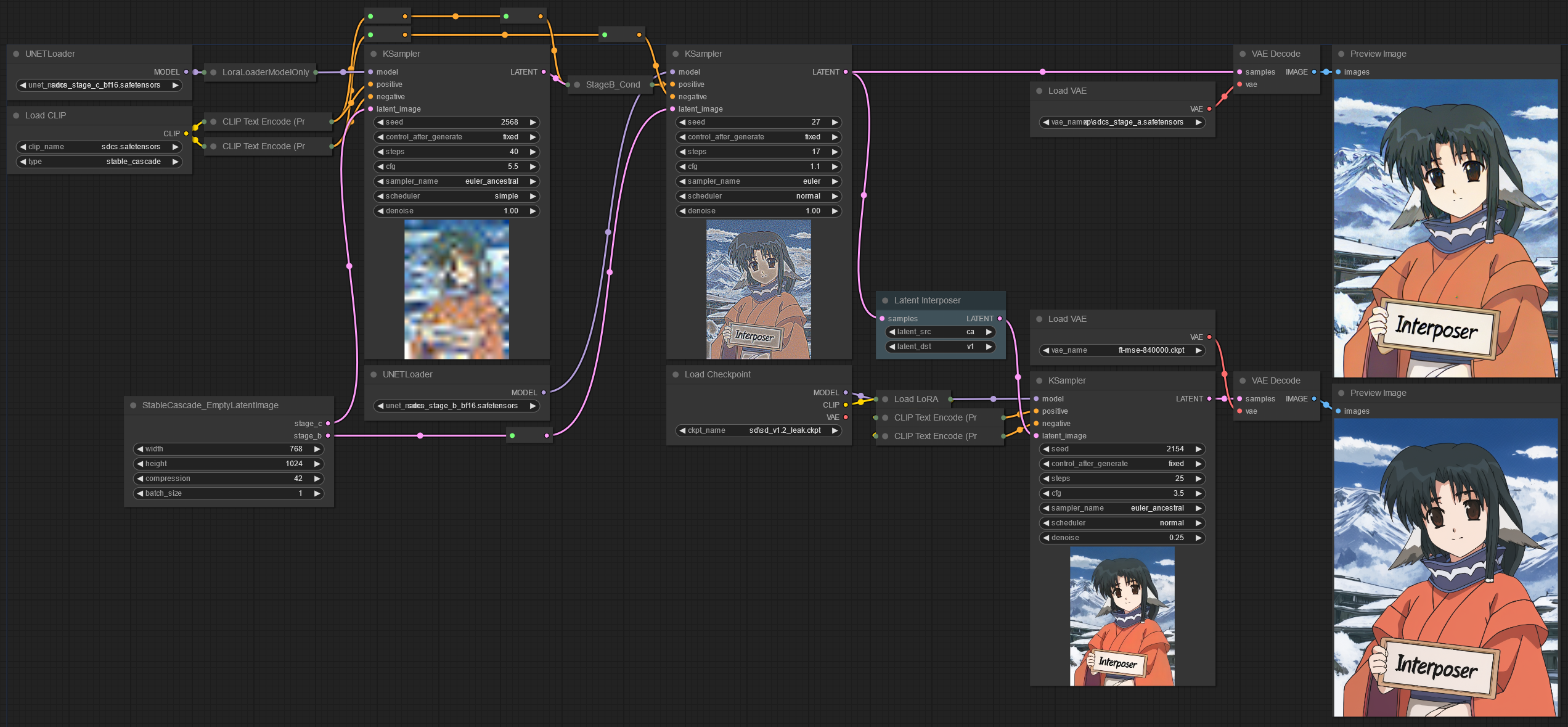
Latent Interposer V4.0
The latent interposer repo to convert between different Stable Diffusion versions without the need for VAE encoding/decoding has been updated to support Cascade stage B. The model architecture and training code have also been updated, so it’s marginally better for XL/v1 as well. It also doesn’t reload the model on each run, making it a bit faster when doing multiple runs without changing models.
Training
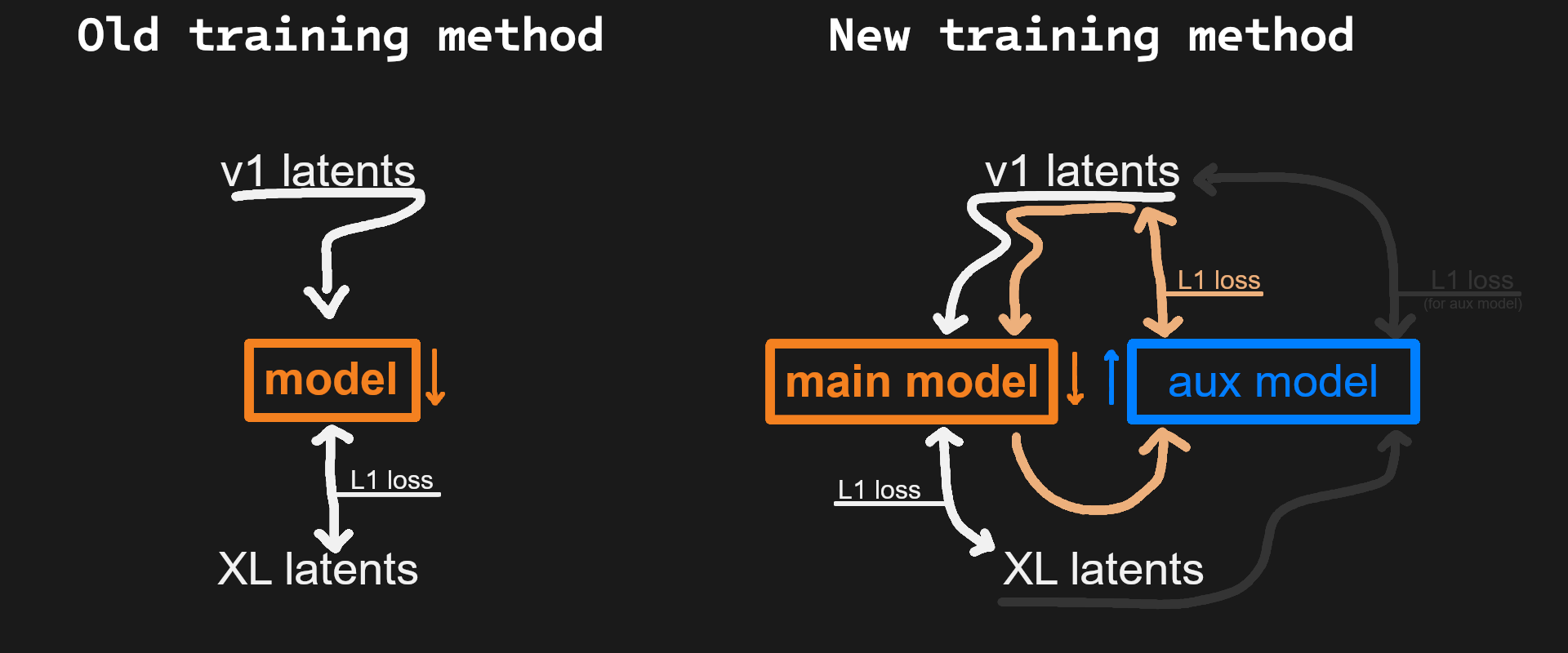
The dataset has been expanded to 88K real life and 50K anime images at 256px, encoded with the respective VAE models. The interposer model now has an internal scale factor, allowing it to convert between different scale latent spaces (i.e. cascade B->SDXL). The original plan was to train a GAN but the training was too unstable and the image quality never improved past that of the current janky double-model training script.
The old training code only used L1Loss (MAE) as the criterion. The new code trains a second model which learns to do the conversion backwards, and considers both the output of the first model as well as the total round-trip of passing it back through the second model.