Anime Classifier - Image Compression
Code | Live Demo | Model download
Excerpt from readme. Click any of the links above for more info.
Design goals
The goal was to detect compression artifacts in images.
This seems like the next logical step in dataset filtering. The flagged images can either be cleaned up or tagged correctly so the resulting network won’t inherit the image artifacts.
Issues
- Low accuracy on 3D/2.5D with possible false positives.
Training
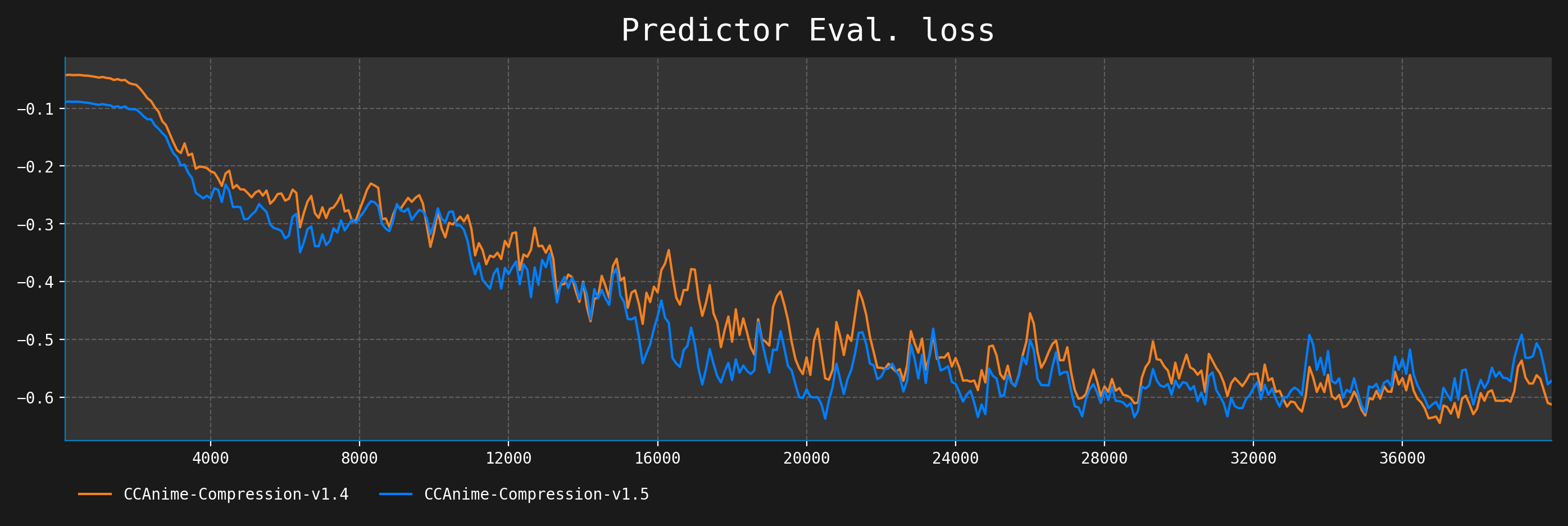
The training settings can be found in the config/CCAnime-Compression-v1.yaml file (2.7e-6 LR, cosine scheduler, 40K steps).
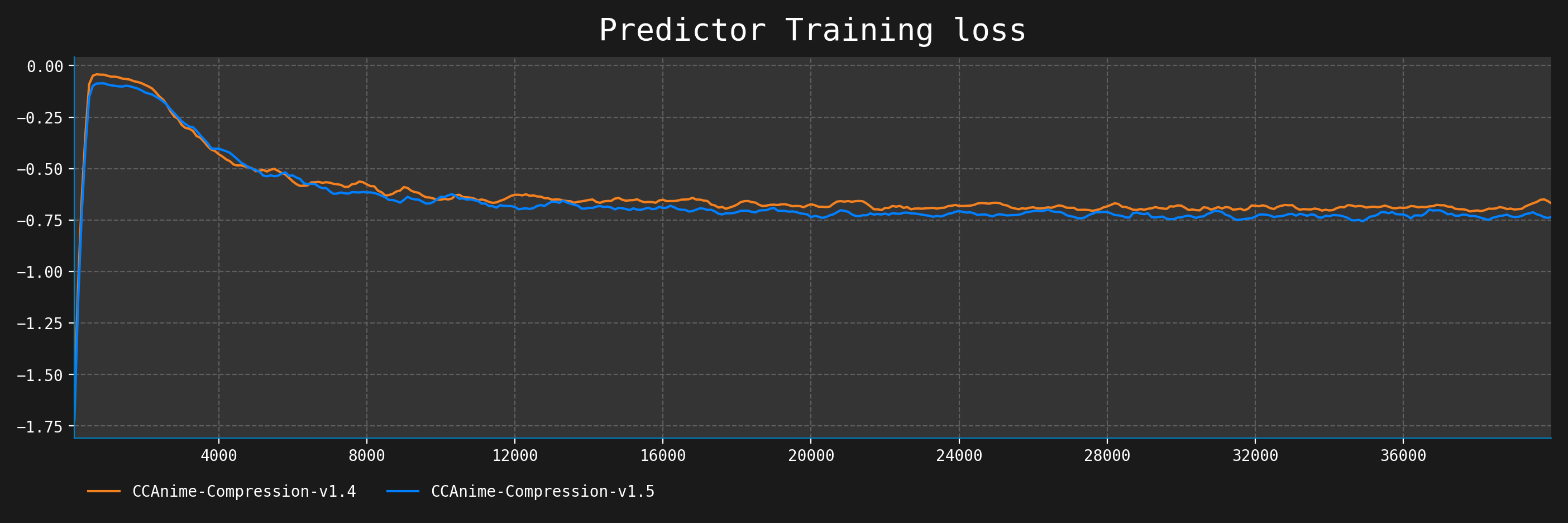
The eval loss only uses a single image for each target class, hence the questionable nature of the graph.
Final dataset score distribution for v1.5:
22736 images in dataset.
0_fpl - 108
0_reg_aes - 142
0_reg_gel - 7445 |||||||||||||
1_aes_jpg - 103
1_fpl - 8
1_syn_gel - 7445 |||||||||||||
1_syn_jpg - 40
2_syn_gel - 7445 |||||||||||||
2_syn_webp - 0
Class ratios:
00 - 7695 |||||||||||||
01 - 7596 |||||||||||||
02 - 7445 |||||||||||||
Version history:
- v1.0 - Initial test model, dataset consists of 40 hand picked images and their jpeg compressed counterpart. Compression is done with ChaiNNer, compression rate is randomized.
- v1.1 - Added more images by re-filtering the input dataset using the v1 model, keeping only the top/bottom 10%.
- v1.2 - Used the newly trained predictor to filter the existing datasets - found ~70 positives in the reg set and ~30 false positives in the target set.
- v1.3 - Scraped ~7500 images from gelbooru, filtering for min. image size of at least 3000 and a file size larger than 8MB. Compressed using ChaiNNer as before.
- v1.4 - Added webm compression to the list, decided against adding GIF/dithering since it’s rarely used nowadays.
- v1.5 - Changed LR/step count to better match larger dataset. Added false positives/negatives from v1.4.